5 Teknologier og arkitekturer for datadeling

Deling av data kan være teknisk utfordrende selv internt i en organisasjon, hvor ulike systemer, filformater og sikkerhetstiltak kan hindre effektiv distribusjon av data. Barrierene har likevel blitt mindre siste årene, med fremveksten av plattformer og skytjenester som kan skaleres etter behov og tjenester som i større grad er bygget for å kunne snakke sammen. Kompleksiteten øker imidlertid når data skal deles i verdikjeder i næringslivet og mellom virksomheter. For aktører som ikke allerede har god kontroll på omfanget og bruken av egen data kan det virke overveldende å skulle tilrettelegge for deling med eksterne parter.
For at data skal være nyttige for andre, må de gjøres tilgjengelige på en måte som gjør det mulig for aktørene å realisere verdien av dem. For at dette skal skje, må data være søkbare, ha god kvalitet, og de må kunne kobles til andre datasett på en trygg og effektiv måte. Det er derfor viktig at datasett er komplette og oppdaterte og beskrevet med gode metadata, og at de er maskinlesbare
Kilde: Meld.St. 22 (2020–2021) Data som ressurs – datadrevet økonomi og innovasjon
Ulike bransjer og firmaer kan ha ulike språk for og ulik forståelse av sine data. Innen f.eks. bank og helse-næringen er dette språket og forståelsen i stor grad standardisert, men det er ikke alltid tilfelle i den tradisjonelle industrien, som gjerne opererer med ulike benevnelser og har ulik forståelse av data. Dette kompliseres også av at industrien ofte har en kombinasjon av data fra tradisjonelle systemer og data fra nye IoT-baserte maskiner og sensorer.
De tekniske utfordringene knyttet til deling av data kan grovt deles i to hovedkategorier – Standarder og arkitektur. Standarder er utbredte og felles regler for hvordan noe skal lagres eller gjennomføres. En dataarkitektur er sammensetningen av modeller, regler og standarder som styrer hvilke data som samles inn, hvordan de lagres, arrangeres, integreres og tas i bruk i datasystemer og organisasjoner.
5.1 Hvordan gjøre virksomhetens dataressurser tilgjengelig?
For at data som produseres av en part skal kunne brukes av en annen, er man avhengig av at dataene er forståelige. Det hjelper ikke at en person sender deg en epost med interessant informasjon, dersom den er på et språk du ikke forstår, eller om du ikke har rett program for å lese eposten. Et datasystems evne til å snakke med og forstå et annet system, kalles interoperabilitet.
Interoperabilitet i sammenheng med datadeling, handler både om systemers evne til å utveksle data, såkalt syntaktisk interoperabilitet, og om evnen til å forstå og koble data sammen på tvers av systemer, såkalt semantisk interoperabilitet.
Syntaktisk interoperabilitet handler altså om teknisk evne til å kommunisere på tvers av systemer. Det er ulike tekniske løsninger for dette. Et eksempel for utveksling av data, er bruken av åpne standardiserte API-er (se tekstboks). Et annet eksempel, er datautveksling mellom industrielle systemer for eksempel i et prosess-anlegg, hvor Open Platform Communication – Unified Architecture (OPC UA) har blitt en viktig brikke, og er bl.a. sentral i Industri 4.0-arbeidet (se kap. 5.4.2).
I tillegg trenger systemene også semantisk interoperabilitet. De må ikke bare evne å lese dataene, men også forstå for eksempel hvilke type utstyr en sensor-verdi relaterer seg til, hvilke posisjoneringssystem som er brukt for en geografisk referanse, hvilke måleenheter verdier er oppgitt i, og hvordan ulike objekter relaterer seg til hverandre. Sentrale elementer her er bruk av data- og industri-standarder, felles datamodeller og referansedata. Dette er arbeid som kan være krevende på tvers av systemer innad i en virksomhet, og som krever desto mer innsats når dette skal gjøres på tvers av virksomheter, eller også på tvers av industrier. Utstrakt bruk av åpne, gjerne industri-uavhengige, standarder, vil i denne sammenhengen være viktig. Her kreves det da også samarbeid på tvers av relevante aktører i økosystemet. OSDU (se kap. 5.4.3) er et eksempel på et slikt arbeid.
Boks 5.1 Åpne API-er
Digital 21-rapportens forslag til prinsipper som danner grunnlaget for bruk av åpne API-er:
- For å forenkle sikkerhetsarbeidet og gjøre det enklere for brukerne av portalen, må tilgang styres vi et felles autentisering- og tilgangskontrollsystem
- For å sikre effektiv tilgang og mulighet for bakgrunnsoppdateringer må det kreves av alle leverandører av IT-systemer til det offentlige at det utvikles API-er på en felles standard som gjør at man kan hente ut data fra systemet på en programmatisk måte.
- Det må gjøres en vurdering av om data som kan knyttes til et individ, må anonymiseres før de gjøres tilgjengelige. Til dette formålet må det brukes lettleste standardkontrakter, men med reservasjonsrett for individet.
- For å sikre videreutvikling av portalen må ekstern tilgang være uavhengig av interne teknologivalg i portalen.
- All uthenting av data fra kildesystemer til portalen må skje automatisk og regelmessig, slik at data ikke blir utdaterte
Boks 5.2 FAIR (Findable, Accessible, Interoperable, Reusable)-prinsippet for deling av data
FAIR som prinsipp ble i 2016 opprinnelig foreslått av en gruppe forskere som kom med anbefalinger og retningslinjer i forbindelse med deling av forskningsdata. På grunn av nytte og relevans har prinsippet imidlertid blitt anvendt i andre områder enn forskning hvor deling av data står sentralt. FAIR-prinsippet er derfor også relevant i forbindelse med deling av industridata.
Findable Det første steget i å kunne bruke (eller gjenbruke) data er at man må finne dataene. Data og metadata må derfor være enkelt å finne, enten manuelt eller automatisk. Maskinlesbare formater er derfor nødvendige for å kunne finne frem til datasett. Det gjøres ved at: F1: (Meta)data gis globalt unike og vedvarende idenfitikatorer. F2: Data er godt beskrevet med metadata (som definert i R1). F3. Metadata inneholder klart og tydelig identifikatorene til dataen de beskriver. F4. (Meta)data registreres og indekseres i en søkbar ressurs
Accessible Når man har funnet frem til data, må man kunne vite hvordan man får tilgang til dem, og hvilke autentifikatorer og autorisasjoner som er nødvendige. Det gjøres ved at: A1. (Meta)data er gjenfinnbare basert på identifikatorer gjennom en standardisert kommunikasjonsprotokoll. A1.1. Protokollen er åpen, gratis og universelt implementerbar. A1.2. Protokollen gir mulighet til å autentisere og autorisere dersom nødvendig. A2. Metadata er tilgjengelig, selv når dataen ikke lengre er det.
Interoperable Dataen må vanligvis være integrerbar med annen data. I tillegg må dataen være interoperatibel med systemer for analyse, lagring og prosessering. Det gjøres ved at: I1. (Meta)data bruker et formelt, tilgjengelig, delt og bredt akseptert språk. I2. (Meta)data bruker et vokabular som følger FAIR-prinsippene. I3. (Meta)data inkluderer referanser til annen (meta)data.
Reusable Formålet med FAIR er å optimalisere for gjenbruk av data. For å få til dette, bør metadata og data være godt beskrevet slik at det kan kopieres og eller settes sammen i andre settinger. Det gjøres ved at: R1. (Meta)data er rikt beskrevet med flere relevante og nøyaktige attributter. R1.1. (Meta)data er sluppet med klare og tilgjengelige bruksvilkår. R1.2. (Meta)data bruker domenerelevante standarder.
5.2 Arkitektur og plattformer
En god og gjennomtenkt arkitektur vil ikke bare være helt sentralt for en virksomhets evne til å lykkes med sine digitaliserings-ambisjoner, men er også viktig for å muliggjøre effektiv og hensiktsmessig deling av data. Et nøkkelelement i digitalisering er å hente ut data fra fagsystemene de er generert- eller lagret i, for å legge til rette for bruk og analyse av data på tvers av ulike systemer. Den rådende tilnærmingen til dette, er å utnytte plattform-tenking, slik at data gjøres tilgjengelig ved hjelp av ulike teknologier i en dataplattform.
Tradisjonelt har slike dataplattformer dreiet seg om ulike former for såkalte datavarehus-løsninger. I dag kalles denne arkitekturen ofte for 1. generasjons dataplattformer. Her tilbys forvaltede data basert på antatte brukerbehov. Styrken til disse har vært kontroll og kvalitet på dataene som tilbys, mens den største utfordringen har dreid seg rundt hvor omfattende og komplekst det blir å gjøre endringer etter hvert som systemene vokser.
Det har gjennom de siste årene vært en forholdsmessig stor utvikling innen dette området, lang på vei drevet frem av den økende rollen dataanalyse og kunstig intelligens spiller i digitaliseringen. For å møte et økt behov for fleksibilitet, skalering og kost-effektivitet, vokste datasjø-teknologiene (data lakes) frem som en neste-generasjons dataplattform-teknologi. Her la man til rette for økt fleksibilitet med hensyn til hva slags innhold som kunne lagres (strukturerte, semistrukturerte eller ustrukturerte data). Hovedfordelen med dette var at man i liten eller ingen grad måtte forberede dataene for en spesifikk bruk når de ble gjort tilgjengelig i plattformen (såkalt Schema-on-write), men gjorde heller denne jobben når dataene skulle brukes (såkalt Schema-on-read). Selv om dette generelt har gitt en betydelig større frihet til å velge hva dataene brukes til enn tidligere, har det også ført til at dataene må bearbeides i hvert enkelt tilfelle. I tillegg kan en slik løsning også resultere i at tilliten til dataene er redusert, sammenliknet med de forvaltede datasettene som er gjort tilgjengelig i et datavarehus.
For å adressere utfordringene med datasjøene, vokste det frem en ny generasjon data-plattformer som kombinerte dataforvaltningsmekanismene i datavarehus med fleksibiliteten til datasjø, ofte kalt datasjøhus (data lake house). Disse plattformene tilbyr gjerne både strømming av sanntidsdata, samt strukturerte, semistrukturerte og ustrukturerte data. Utfordringen med disse plattformene har i en del tilfeller vist seg å være kompleksiteten i ende-til-ende behandlingen av dataene, som kan resultere i ny usikkerhet om datakvaliteten. Eksempel på slike usikkerheter kan være i hvilke grad konsumenten kan stole på at det ikke er forsinkelser i sensor-verdiene som brukes til å avlese utstyr, at det ikke forekommer konverteringsfeil i dataenes reise fra kilde til konsument og lignende. Dette er spesielt viktig dersom data skal benyttes i operasjonelle sikkerhetskritiske prosesser og sentrale beslutningsprosesser.
De siste årene har nye konsepter, deriblant en sterkere produkt-tenkning rundt data, vokst frem. Tidligere generasjoner av dataplattformer har i stor grad har hatt en klar sentralisert tilnærming. Dette er også tilfelle for noen av de nye tilnærmingene, som for eksempel Data Fabrics. Andre, som for eksempel Data Mesh, bygger på mer desentraliserte modeller, for å møte utfordringene spesielt større selskaper har relatert til skalering av dataforvaltning.
5.3 Arkitekturer for datadeling
Ulike aktører i ulike næringer vil ha forskjellige behov for teknologiske løsninger. Mens det for noen aktører vil være hensiktsmessig å dele data på en felles plattform, vil andre – for eksempel av sikkerhetshensyn– dele data direkte, basert på konkrete behov eller forretningsprosesser.
Vi kan dele de ulike arkitekturene i tre hovedkategorier – distribuerte, fødererte og sentraliserte arkitekturer. I den mest elementære settingen for datadeling avtaler to (eller flere) virksomheter å dele data seg imellom gjennom for eksempel tilgang til APIer. Dette er et distribuert system. Distribuerte systemer er forholdsvis enkle å implementere mellom et fåtall aktører, men egner seg i mindre grad til mer avansert deling mellom mange aktører ettersom kompleksiteten i systemene er forholdsvis lav.
I såkalte fødererte arkitekturer forblir lagringen hos den aktøren som produserer data, men i motsetning til en distribuert arkitektur har utarbeidet et felles rammeverk eller sett av regler for sikkerhet, standarder, validering og bruk av data.
I sentraliserte arkitekturer, slik som dataplattformer, lagres partenes datasett blir hos en sentral aktør. Leverandøren av infrastrukturen vil i dette tilfellet gjerne også ha ansvar for interoperabilitet og sikkerhet i arkitekturen. Plattformleverandøren vil også i mange tilfeller tilby datadrevne tjenester inn i plattformen også, som analyseverktøy basert på kunstig intelligens.
I realiteten vil mange virksomheter måtte forholde seg til flere av disse i parallell, innenfor ulike deler av virksomheten. Det opereres også i mange tilfeller med kombinasjoner av disse modellene.
5.3.1 Sikkerhet og tillit i datadeling
Tillit er en av de grunnleggende forutsetningene for deling av data. Hvis aktører ikke har tillit til hverandre vil ikke insentivene for datadeling være tilstrekkelige til at en virksomhet tar kostnaden av å eksponere data. Tillit må være etablert på tre nivå:
- Organisasjonsmessig tillit: Har aktørene de samme intensjonene med datadeling? Er det etablerte samarbeidsrelasjoner mellom aktørene? Vil deltagelse i dataøkonomien veie opp for kostnaden ved å dele? Vil alle aktørene bli inkludert i forretningsmodellene som oppstår på grunn av tilgang til data? Vil dataprodusenten holdes ansvarlig for følgene som oppstår på grunn av dårlig kvalitet i datasettene som deles?
- Tillit til infrastrukturen: Hvordan sikrer infrastrukturen at uvedkommende ikke får tilgang til aktørenes data? Er infrastrukturen robust nok til å motstå cyber-angrep? Ivaretar infrastrukturen transparens og integritet i data-transaksjonene?
- Tillit til data: Er data som en virksomhet mottar av høy nok kvalitet? Er dataene komplette og korrekte? Vil data som mottas kunne forårsake utilsiktede konsekvenser for produksjon eller andre prosesser? Hvordan sikre at delte datasett ikke blir manipulert eller brukt på en uønsket måte?
Mens et godt utarbeidet avtaleverk kan øke (eller, til en viss grad, erstatte) den organisasjonsmessige tilliten er det viktig at det tekniske rammeverket rundt datadelingen legger opp til en tillitsinfrastruktur gjennom bruk av gode praksiser innen informasjonssikkerhet, robusthet og autentisering av deltagerne, uansett av hvilken arkitektur som brukes.
Der tilliten mellom aktørene er lav finnes det nyere teknologier som muliggjør felles bruk av aktørenes data uten å avsløre disse for hverandre, som for eksempel innen såkalt føderert maskinlæring, secure multiparty computation eller homomorfisk kryptering av data, som tillater operasjoner som beregninger eller maskinlæring på kryptert data. Mens de mest avanserte av disse «privacy-preserving technologies» fortsatt er gjenstand for forskning, finnes det allerede kommersielle plattformer for føderert maskinlæring eller secure multiparty-computation.
5.4 Relevante initiativer
5.4.1 European data spaces
Konseptet av «European Data Spaces» er forankret i EU-kommisjonens strategi for data, som ett av de sentrale tiltakene for den europeiske dataøkonomien. Data Spaces, som infrastrukturer for deling av data skal bidra til:
- Flyt av data innenfor ulike industrivertikaler på tvers av Europa
- Tilgjengelighet av høykvalitets industridata som akselerator for datadrevet innovasjon
- Deling av data i tråd med europeiske verdier og reguleringer
- Et bedre regelverk for tilgang til – og bruk av – industridata med forståelige og rettferdige mekanismer for styring (governance) av data.
Ulike brukergrupper vil ha ulike behov for deling av data som igjen vil resultere i ulike tilnærmingsmåter med tanke på arkitektur, informasjonssikkerhet, tilgang til data etc. Derfor har EU-kommisjonen definert ni ulike sektorer der europeiske data spaces skal opprettes:
- Helse
- Industri og vareproduksjon
- Landbruk
- Finans
- Mobilitet
- Det grønne skiftet
- Energi
- Offentlig sektor
- Forskning og utdanning
På hvert av disse områdene skal det utvikles de nødvendige teknologiske verktøyene for datadeling og -utveksling i tillegg til lagrings- og prosesseringstjenester i skyen, samt standarder og metoder for teknisk og semantisk interoperabilitet.
Det er grunn til å anta at europeiske infrastrukturer for datadeling vil ha en betydning for norske aktører, spesielt innen eksport-orienterte sektorer som for eksempel energi eller sjømatproduksjon. Dersom de opprettede data spaces brukes i digitaliseringen av verdikjedene innenfor de nevnte sektorene er det viktig for norske aktører å være i posisjon for å kunne slutte seg til disse økosystemene. Utover dette vil det ligge et læringspotensial i den anvendte teknologien for gjenbruk i norsk sammenheng.
De europeiske Data Spaces vil implementeres og rulles ut gjennom Digital Europe Programmet (DIGITAL). EU-kommisjonen anslår å investere 410 millioner euro i Data Spaces gjennom en blanding av bevilgninger (grants) og offentlige anbud (tenders). Siden Norge deltar i DIGITAL innebærer dette et mulighetsrom for norske aktører, ikke bare for å benytte seg av infrastrukturene som bygges, men også bidra til utformingen av disse.
5.4.2 Industri 4.0
Det er tidligere i rapporten pekt på viktigheten av interoperabilitet. For å oppnå dette, er det enda viktigere enn tidligere for virksomheter å finne felles og standardiserte løsninger, slik at prosessene og økosystemene de opererer i blir mer kostnads- og utslipps-effektive, og at det legges til rette for økt fleksibilitet og innovasjon. Samtidig må sikringen av systemene styrkes, heller enn svekkes. I denne sammenhengen vil Industri 4.0 være relevant for en del virksomheter å sette seg inn i.
Industri 4.0, også referert til som den fjerde industrielle revolusjon, er en digital transformasjon av bransjer hvor grensen mellom fysiske eiendeler og industriell produksjon, og den digitale verden blir mer og mer utydelig og sammenflettet. Fysisk utstyr blir «intelligent», kan kommunisere og samspille med annet utstyr, og er i økende grad i stand til å drive, kontrollere og optimalisere produksjonsprosesser av seg selv uten menneskelig innblanding.
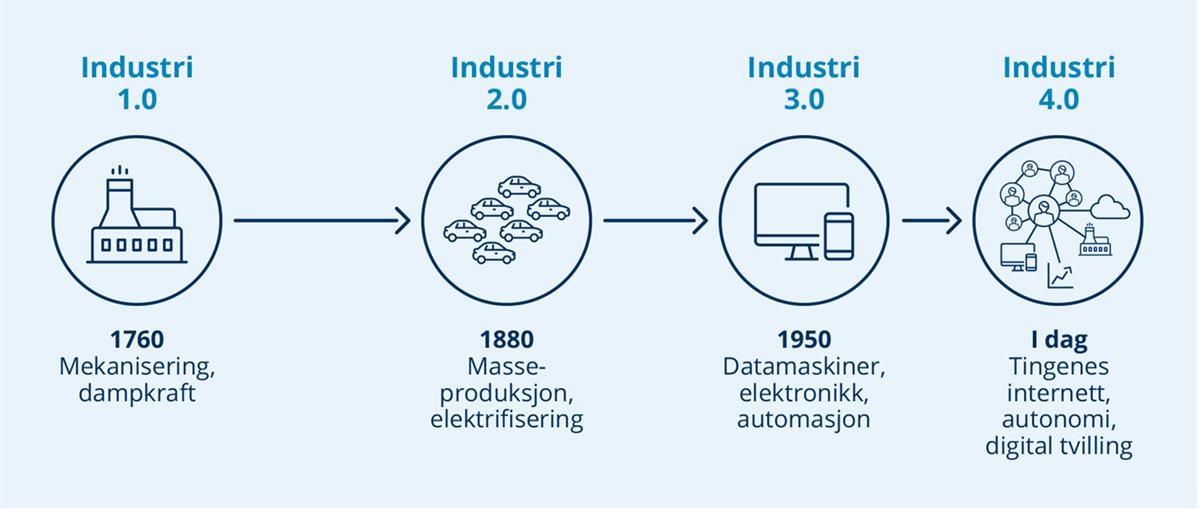
Et nøkkelelement i Industri 4.0, er at alle fysiske komponenter har en digital tvilling som er tilgjengelig for både mennesker og maskiner i hele verdikjeden. Den digitale tvillingen blir kontinuerlig beriket og brukt til overvåking, simulering og optimalisering gjennom hele livssyklusen, fra design til avhending.
Det Industri 4.0 primært bidrar med i denne sammenhengen, er å sikre interoperabilitet mellom de ulike komponentene i verdikjeden, for på den måten å understøtte nye data drevne-forretningsmodeller. Dette gjøres blant annet ved hjelp av standarder for hvordan data kan kobles sammen, hvordan systemer kan utveksle data på en sikker og hensiktsmessig måte, og tekniske komponenter for hvordan sette opp og utvikle digitale tvillinger.
5.4.3 The Open Group OSDU Data Platform
I mange tilfeller vil viktige løsninger til datadelings-utfordringer kreve industrispesifikt samarbeid. Et eksempel på et slik samarbeid er The OpenGroup’s OSDU Data Platform for undergrunnsdata.
Dagens marked for programvare relatert til undergrunnsdata kjennetegnes av et fåtall dominerende leverandører. Data spres på tvers av ulike databaser, og låses inne i programvare-siloer, eller gjøres utilgjengelig gjennom bruk av proprietære datamodeller. Dermed blir effektiv forvaltning og fleksibel bruk av dataene vanskelig. Dette gjør det igjen vanskelig for nye aktører å entre markedet, og dermed begrenses innovasjonen ytterligere.
OSDU startet som et samarbeid mellom sentrale olje- og gass-operatører (Shell, Chevron, Equinor, Conoco Phillips, BP og Total) i 2018, basert på en felles forståelse at den pågående energi-transformasjonen krever samhandling og åpenhet for å lykkes. Ingen av disse operatørene mente at de ville kunne lykkes med dette på egen hånd, og så her sentrale områder hvor de ville tjene på samarbeide, fremfor å konkurrere. Per dags dato har OSDU ca. 200 medlemsbedrifter, og inkluderer store skyleverandører som Microsoft, Google, Amazon og IBM, de sentrale programvare-leverandørene innen undergrunnsdata (Schlumberger, Halliburton), i tillegg til store konsulent- og tjenesteleverandører, software-selskaper med mer. I dette tilfellet hadde operatørene en felles utfordring, mens de store skyleverandørene så et mulighetsrom. For programvareleverandørene var bildet mer sammensatt, hvor dette for noen kunne være en utfordrer til eksisterende forretningsmodeller, samtidig som det la til rette for fremveksten av nye modeller.
Det OSDU har til hensikt å utvikle, er en standardisert dataplattform, basert på åpen kildekode, hvor data separeres fra applikasjonene og tilgjengeliggjøres gjennom standardiserte grensesnitt. Dette vil videre kunne implementeres som Software as a Service (SaaS) hos de store skyleverandørene, og dermed også legge til rette for standardiserte grensesnitt som software-leverandørene kan levere produkter tilpasset.
Det overordnede verdipotensialet i OSDU knytter seg til redusert friksjon i eksisterende forretningsprosesser gjennom økt interoperabilitet, forbedret databehandling og forbedret datakvalitet, herunder sporing av hvordan data endres over tid. OSDU gjør det enklere å fange, berike, finne og bruke data. Videre, gjennom en felles plattform og standardiserte grensesnitt, legger man til rette for en ny generasjon digitale løsninger som støtter nye måter å jobbe på. Denne innovasjonen vil igjen bidra tilbake til videreutviklingen av plattformen.
Det har nå gått 3 år siden første oppstartsmøte i OSDU og de første kapabilitetene er nå klare for produksjonssetting hos fire av de største skytjenesteleverandørene. Mye arbeid gjenstår for å få kapabiliteter som dekker alle arbeidsflyter og fagområder på plass, men dette er hva OSDU-organisasjonen er satt opp for å kunne levere på i årene som kommer. OSDU er en fleksibel dataplattform som, selv om fokuset nå er på undergrunnsdata, på sikt potensielt også vil kunne bidra innenfor andre domener. På nåværende tidspunkt er likevel den viktigste erfaringen en kan ta med seg til andre industrier hvordan problemstillingen har blitt adressert i OSDU. Noen av nøkkel-elementene som har utkrystallisert seg som sentrale så langt, er:
- Felles problemstilling og/eller sammenfallende interesser på tvers av sentrale aktører er den viktigste driveren bak et vellykket samarbeid, og bør tillegges mye fokus, spesielt tidlig i prosessen.
- Beslutsomhet og utholdenhet. Å lykkes i en transformasjon av denne størrelsesordenen krever prioritering, investering og fokus over tid.
- Utvikling av standarder som en del av utvikling av programvare, og ikke som en selvstendig teoretisk øvelse, bidrar til implementerbare standarder med pragmatiske tilpasninger.
- Involvering av alle sentrale deler av økosystemeter er viktig for å kunne lykkes med å transformere dette økosystemet.